Synthetic Personas: What the Evidence Actually Shows, and How to Deploy Them Responsibly
2026-06-04

In the land of MarTech, there's a new kid... er, bot on the block.
Synthetic personas are AI-generated representations of target audiences, and they've graduated from a buzzword to a legitimate research methodology. Legitimate, though, comes with conditions.
The core premise is straightforward: instead of waiting months for members to complete a research cycle, you build AI-generated representations of your target audience and run them through the same stimuli at a fraction of the time and cost. Think of it like this. Instead of asking your grandmother whether a new Medicare supplement communication is clear enough for her to act on, you create hundreds of grandmother-like personalities, simulate a panel of them, and build a probabilistic model of how people like her will respond. A 2025 study published on arXiv found that well-constructed synthetic personas can reach approximately 90% of human test-retest reliability when using semantic similarity elicitation methods.1 They are not a substitute for human research. But they are no longer a toy, either.
For organizations whose members trust them with sensitive life decisions (healthcare navigation, retirement planning, benefits enrollment), that distinction matters enormously. Synthetic personas appear to work in principle. The harder question is whether you and your implementation partner understand the failure modes well enough to avoid them.
What a Synthetic Persona Is, and What It Isn't
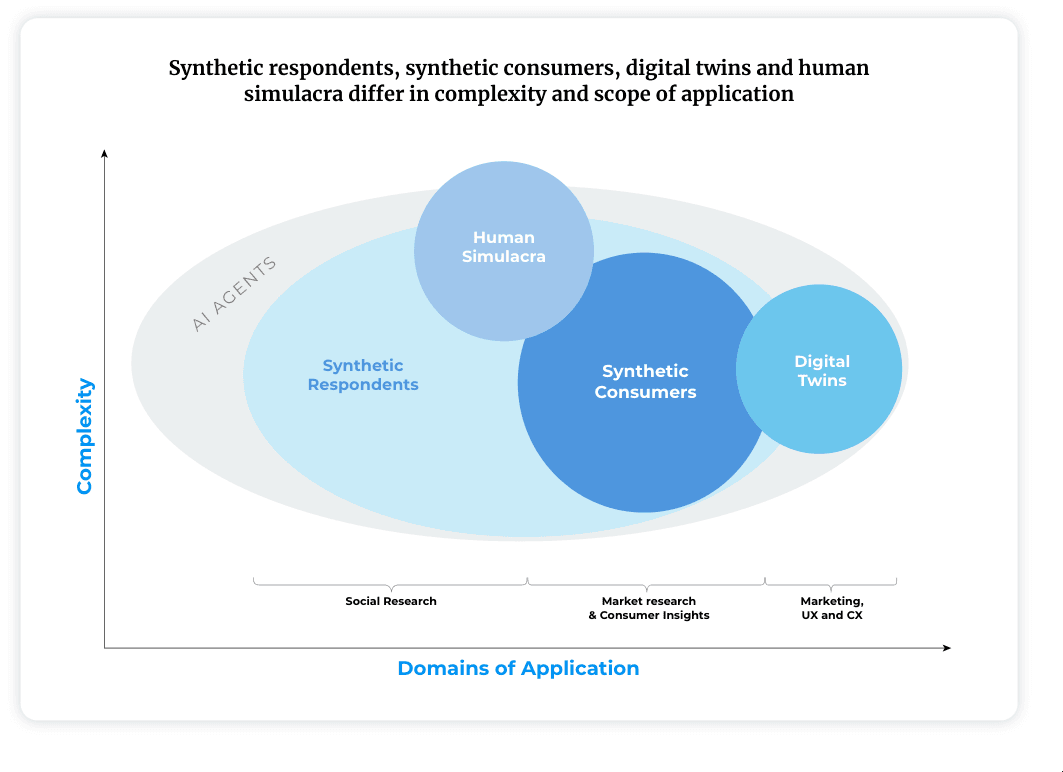
The term "synthetic persona" covers a spectrum of tools with meaningfully different capabilities and risk profiles. PyMC Labs, which has published some of the most rigorous applied work in this space, identifies four subtypes:2
- Synthetic Respondents: Generalist agents that simulate survey responses. Useful for opinion research and directional signals on questions like messaging preference or policy position framing.
- Synthetic Consumers: Purpose-built agents instructed to think and behave like a defined personality profile. Used to model behavior, not just stated opinion.
- Digital Twins of Consumers: Continuously updated models calibrated to a specific individual's documented behaviors over time. Requires rich longitudinal data.
- Human Simulacra: High-fidelity models of group dynamics and emergent behavior. Currently more active in academic research than in production deployments.
For most practical applications, the operative type is Synthetic Consumers: purpose-built behavioral agents trained on defined demographic, psychographic, and behavioral profiles. The rest of this article focuses there.
Synthetic persona agent framework. Source: Cognizant, "The Rise of Synthetic Users".
The distinction between subtypes is not academic. A Synthetic Respondent can tell you whether a proposed benefits communication feels clear to a given member segment. A Synthetic Consumer can simulate whether that member actually completes an enrollment flow, or where they drop off and why. Conflating the two leads to over-reliance on shallow opinion signals, or overpromising on behavioral fidelity the underlying model cannot support. Both are expensive mistakes.
Where Synthetic Personas Add Real Value
Before getting into specifics, the structural advantage is worth naming directly. A traditional research cycle, recruiting participants, fielding the study, analyzing results, synthesizing findings, takes weeks to months and costs anywhere from tens to hundreds of thousands of dollars for a well-instrumented study. A synthetic persona pipeline running the same stimulus can return directional signal in hours, at a fraction of the cost.
That time and cost advantage does two things. It makes existing research cheaper, and it makes a whole category of testing economically viable that previously wasn't worth running. Questions that didn't clear the ROI bar for a full research cycle become tractable. The organizational implication is real: a research culture that can move at the speed of the questions, not the budget cycle.
Member Communication Testing
Consider an organization preparing to roll out a redesigned benefits enrollment experience ahead of an open enrollment window. The membership spans multiple life stages: adults in their fifties approaching Medicare eligibility, retirees navigating supplement options for the first time, members with complex chronic condition management needs. Traditional A/B testing requires live traffic, weeks of data collection, and real members exposed to potentially confusing or suboptimal messaging during a high-stakes decision period.
A synthetic persona pipeline can simulate panel responses across each segment in hours. Using a browser automation tool, synthetic consumers can navigate the full enrollment flow, surface friction points, and generate preliminary signal on which communication variants perform better by segment, all before a single real member encounters them.
The operative word is "preliminary." This is directional intelligence, not a final answer. That distinction is important enough that we address it directly in the limitations section below.
Member Segmentation
Demographic data describes who your members are. Behavioral segmentation describes what they actually do, and the two frequently diverge in ways the demographic data cannot predict.
Synthetic personas can surface latent behavioral clusters that traditional segmentation misses. Members who share the same age cohort and income bracket may behave entirely differently in a benefits decision context depending on health status, prior engagement history, or proximity to a life transition. These patterns typically require computationally expensive data mining to identify from first principles. Synthetic personas can generate testable hypotheses about them faster and at lower cost, with the explicit requirement that those hypotheses get validated against real behavioral data before informing strategy.
Research You Couldn't Afford to Run Before
This is the most underappreciated application of the technology, and arguably the most valuable one.
Every organization has a backlog of hypotheses that never make it onto the research calendar. Small message variants, niche segment behaviors, early-stage program concepts that may not move forward, edge cases that affect a meaningful but not statistically convenient slice of membership. These questions don't clear the ROI bar for a full research study. So they don't get answered. Decisions get made on instinct or get deferred entirely.
Synthetic personas change that economics. A hypothesis that doesn't justify a full research study budget might easily justify a synthetic persona test that returns directional signal in 48 hours. Run enough of those, validate the reliable ones against real member data, and you have a research capability that compounds over time. The backlog of unanswered questions becomes an asset rather than a liability.
The Limitations That Actually Matter
The honest case for synthetic personas requires engaging seriously with what they cannot do. For a trust-based organization, the failure modes deserve more than a footnote.
They Simulate Language, Not Reasoning
The foundational critique of large language models, articulated rigorously in Bender et al.'s "On the Dangers of Stochastic Parrots" (2021), is that they produce statistically plausible sequences of tokens without any underlying model of the world or the people in it.3 In practice, a synthetic persona can reproduce the form of a decision, the language a member would use to describe their choice, without modeling the actual motivational pathway that drove it.
This matters acutely in a benefits context. A synthetic persona might correctly predict that a member clicks on a Medicare supplement enrollment link. It may completely miss why they hesitate at the confirmation screen, because the hesitation is rooted in a trust dynamic, a prior negative experience with the organization, or a cognitive load the model was never trained to represent. The output looks correct. The underlying mechanism is wrong. Decisions built on it are wrong in ways that are difficult to detect without deliberate validation.
Training Data Does Not Represent Everyone Equally
Models are trained on documented human behavior, which means they inherit the documentation gaps in that data. Demographic groups whose behaviors are underrepresented in the training corpus, older adults with limited digital footprints, members from rural or lower-income backgrounds, non-English-speaking members, will be systematically misrepresented in synthetic outputs.
For a membership organization with a diverse member base, this is not a theoretical concern. It is a concrete risk that under-served segments receive insights based on data that does not actually reflect them. Cognizant identifies this as a "representation distortion" failure mode, one of three categories alongside psychology distortion (personas behaving in cognitively unrealistic ways) and confidence distortion (personas presenting incorrect outputs with high certainty).4
Synthetic Confidence Is Not Validated Confidence
Synthetic personas do not hedge. They assert. Outputs are presented with the same linguistic confidence regardless of whether the underlying signal is reliable. In a stakeholder environment where synthetic persona outputs inform budget decisions or member-facing strategy, this creates a real governance risk: confident-sounding findings that have not been validated against human data can anchor decisions in ways that are difficult to reverse, particularly in organizations where those decisions carry reputational weight.
PyMC Labs is explicit on this point: validation against ground-truth human data is not optional. It is the mechanism that converts a synthetic signal into a defensible finding.5
A Framework for Where to Deploy Them
Not every use case carries equal risk. The framework below maps synthetic persona applications across two dimensions: the cost of being wrong (risk) and the potential upside of being right (reward).
Risk in this context means the material cost of an incorrect finding:
- Resources misallocated from faulty targeting
- Reputational damage from messaging that misreads the membership
- Member trust erosion from a misaligned or confusing experience
- Strategic cost of delayed course-correction in a time-sensitive window, like open enrollment, an advocacy campaign, or a policy response
Reward means the measurable upside:
- Speed and cost: reduced time to signal, lower cost per insight, faster iteration on messaging and product decisions before real members are exposed
- Compounding accuracy: validated synthetic outputs build an increasingly accurate picture of your specific membership behavior over time, not a generalized population
- Unlocked research surface: questions that previously couldn't justify a full study budget become tractable, which means fewer decisions made on instinct and fewer blind spots that only surface after launch

Low Risk, Low Reward: Start Here
Internal communications testing, exploratory segmentation hypotheses, early-stage message variants where no real members are exposed. This is where you build the operational capability, calibrate the methodology against your specific membership, and establish a performance baseline before the stakes are real.
Low Risk, High Reward: Prioritize
Synthetic persona applications with meaningful upside and limited exposure if the signal is imprecise: pre-launch benefits communication testing, enrollment flow friction identification, campaign message variants across member segments. The asymmetric upside here justifies significant implementation investment.
High Risk, High Reward: Proceed With Validated Methodology Only
High-stakes positioning decisions, policy communications to the full membership, advocacy campaign framing on sensitive topics. Only appropriate once the methodology has been validated against real member data and confidence thresholds are well-characterized. This is the long-tail of a mature program, not the entry point.
High Risk, Low Reward: Do Not Deploy Here
If the cost of a wrong answer is high and the upside is marginal, this is not a synthetic persona problem. Use a different method. The availability of the tool does not change the calculus.
How Daktic Digital Approaches This
A program like this is built in layers. The underlying model is one layer, and there are capable suppliers to evaluate and integrate depending on your use case, data environment, and membership profile. The harder layer is everything around the model: the measurement infrastructure, the data pipelines, the feedback loop between synthetic outputs and real member behavior, and the governance criteria that make the outputs defensible. That is where implementation either holds together or doesn't.
Our engagement model is straightforward. We come in as the engineering and data implementation lead, working as an extension of your existing team rather than as a separate entity delivering a pre-packaged solution. That means three concrete commitments.
Supplier selection and integration. We evaluate the model suppliers against your specific requirements, integrate the tooling into your data environment, and own the engineering layer that makes the synthetic panel actually run against your membership profile rather than a generic population.
Measurement infrastructure from day one. Before synthetic personas inform any decision, we build the baseline against real member data and the backtesting pipeline that runs continuously against it. This is the part most implementations skip. Without this, you are not running a program. You are running on faith.
Governance as a first-class deliverable. We define, alongside your team, the criteria for when synthetic outputs require human validation before informing a decision.4 Not after a problem surfaces; before the program scales. That document is as important as the technical implementation, and it is the thing that protects your organization's credibility with its members if the outputs ever get scrutinized.
Conclusion
Done well, synthetic personas represent a genuine step-change in how member organizations can understand and serve the people who rely on them. Faster signal, lower cost, and access to questions that were previously too expensive to ask. The technology is ready, the research is maturing, and the use cases are real.
The variable is implementation. For organizations where the member relationship is the core asset, a poorly constructed program doesn't just waste budget. A flawed segmentation model quietly biases communications for a quarter before anyone notices. A synthetic panel with poor demographic representation shapes an enrollment campaign that works for some members and silently fails others. The difference between those two outcomes is not the technology. It is the rigor of the team building it.
If you are evaluating whether to invest in a synthetic persona program, the right question to ask any implementation partner is not "can you build this?" Most can. The right question is "how will you know if it's working?" The answer to that question will tell you most of what you need to know.
Sources & Citations
Footnotes
-
Benjamin F. Maier et al. (2025), "LLMs Reproduce Human Purchase Intent via Semantic Similarity Elicitation of Likert Ratings," arXiv:2510.08338: the semantic-similarity-rating method reaching ~90% of human test-retest reliability. ↩
-
PyMC Labs, "Synthetic Consumers,": source of the synthetic-persona taxonomy (synthetic respondents, synthetic consumers, digital twins, human simulacra). ↩
-
Emily M. Bender, Timnit Gebru, Angelina McMillan-Major & Shmargaret Shmitchell (2021), "On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?" ACM FAccT, doi:10.1145/3442188.3445922. ↩
-
Melek Akan, "The Rise of Synthetic Users," Cognizant: source of the three distortion failure modes (psychology, representation, confidence) and the case for building governance early. ↩ ↩2
-
PyMC Labs, "Synthetic Consumers: A Practical Guide,": validation methodology, backtesting against human data, and reported accuracy ranges. ↩